

README.md 12 KB
Paddle Lite
English | 简体中文

![]()

![]()
Paddle Lite 是一个高性能、轻量级、灵活性强且易于扩展的深度学习推理框架,定位于支持包括移动端、嵌入式以及边缘端在内的多种硬件平台。
当前 Paddle Lite 不仅在百度内部业务中得到全面应用,也成功支持了众多外部用户和企业的生产任务。
快速入门
使用 Paddle Lite,只需几个简单的步骤,就可以把模型部署到多种终端设备中,运行高性能的推理任务,使用流程如下所示:
一. 准备模型
Paddle Lite 框架直接支持模型结构为 PaddlePaddle 深度学习框架产出的模型格式。目前 PaddlePaddle 用于推理的模型是通过 save_inference_model 这个 API 保存下来的。 如果您手中的模型是由诸如 Caffe、Tensorflow、PyTorch 等框架产出的,那么您可以使用 X2Paddle 工具将模型转换为 PaddlePaddle 格式。
二. 模型优化
Paddle Lite 框架拥有优秀的加速、优化策略及实现,包含量化、子图融合、Kernel 优选等优化手段。优化后的模型更轻量级,耗费资源更少,并且执行速度也更快。 这些优化通过 Paddle Lite 提供的 opt 工具实现。opt 工具还可以统计并打印出模型中的算子信息,并判断不同硬件平台下 Paddle Lite 的支持情况。您获取 PaddlePaddle 格式的模型之后,一般需要通该 opt 工具做模型优化。opt 工具的下载和使用,请参考模型优化方法。
三. 下载或编译
Paddle Lite 提供了 Android/iOS/X86/macOS 平台的官方 Release 预测库下载,我们优先推荐您直接下载 Paddle Lite 预编译库。
Paddle Lite 已支持多种环境下的源码编译,为了避免复杂、繁琐的环境搭建过程,我们建议您使用 Docker 开发环境 进行编译。当然,您也可以根据宿主机和目标设备的 CPU 架构和操作系统,在源码编译方法中找到相应的环境搭建及编译指南,自行完成编译环境的搭建。
四. 预测示例
Paddle Lite 提供了 C++、Java、Python 三种 API,并且提供了相应 API 的完整使用示例:
您可以参考示例中的说明快速了解使用方法,并集成到您自己的项目中去。
针对不同的硬件平台,Paddle Lite 提供了各个平台的完整示例:
- Android 示例 [图像分类] [目标检测] [口罩检测] [人脸关键点] [人像分割]
- iOS 示例
- ARMLinux 示例
- ARM CPU 示例
- X86 示例
- OpenCL 示例
- 百度 EdgeBoard FPGA 示例
- 华为麒麟 NPU 示例
- 华为昇腾 NPU 示例
- 昆仑芯 XPU 示例
- 瑞芯微 NPU 示例
- 联发科 APU 示例
- 比特大陆 NPU 示例
- 晶晨 NPU 示例
- 颖脉 NNA 示例
- 英特尔 FPGA 示例
主要特性
- 支持多平台:涵盖 Android、iOS、嵌入式 Linux 设备、Windows、macOS 和 Linux 主机
- 支持多种语言:包括 Java、Python、C++
- 轻量化和高性能:针对移动端设备的机器学习进行优化,压缩模型和二进制文件体积,高效推理,降低内存消耗
持续集成
| System | X86 Linux | ARM Linux | Android (GCC/Clang) | iOS |
|---|---|---|---|---|
| CPU(32bit) | ||||
| CPU(64bit) | ||||
| OpenCL | - | - | - | |
| Metal | - | - | - | |
| 百度 EdgeBoard FPGA | - | - | - | |
| 华为麒麟 NPU | - | - | - | |
| 华为昇腾 NPU | - | - | ||
| 昆仑芯 XPU | - | - | ||
| 瑞芯微 NPU | - | - | - | |
| 联发科 APU | - | - | - | |
| 比特大陆 NPU | - | - | - | |
| 晶晨 NPU | - | - | ||
| 颖脉 NPU | - | - | - | |
| 英特尔 FPGA | - | - | - |
架构设计
Paddle Lite 的架构设计着重考虑了对多硬件和平台的支持,并且强化了多个硬件在一个模型中混合执行的能力,多个层面的性能优化处理,以及对端侧应用的轻量化设计。
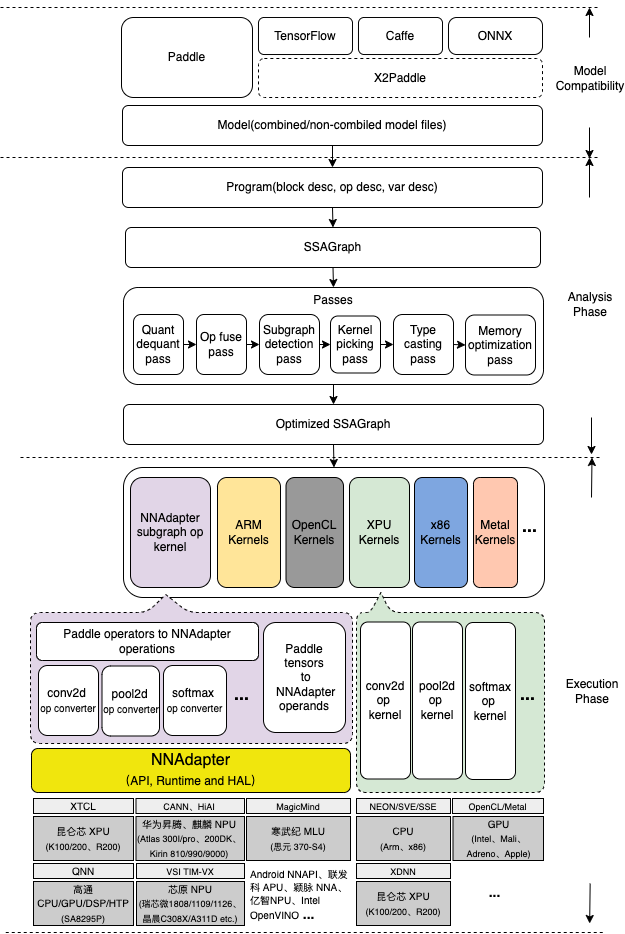
其中,Analysis Phase 包括了 MIR(Machine IR) 相关模块,能够对原有的模型的计算图针对具体的硬件列表进行算子融合、计算裁剪 在内的多种优化。Execution Phase 只涉及到 Kernel 的执行,且可以单独部署,以支持极致的轻量级部署。
进一步了解 Paddle Lite
如果您想要进一步了解 Paddle Lite,下面是进一步学习和使用 Paddle Lite 的相关内容:
文档和示例
- 完整文档: Paddle Lite 文档
- API文档:
Paddle Lite 工程示例: Paddle-Lite-Demo
关键技术
模型量化:
调试分析:调试和性能分析工具
移动端模型训练:点击了解一下
飞桨预训练模型库:试试在 PaddleHub 浏览和下载 Paddle 的预训练模型
飞桨推理 AI 硬件统一适配框架 NNAdapter:点击了解一下
FAQ
FAQ:常见问题,可以访问 FAQ、搜索 Issues、或者通过页面底部的联系方式联系我们 ###贡献代码
贡献代码:如果您想一起参与 Paddle Lite 的开发,贡献代码,请访问开发者共享文档
交流与反馈
- AIStuio 实训平台端测部署系列课程:https://aistudio.baidu.com/aistudio/course/introduce/22690
- 欢迎您通过 Github Issues 来提交问题、报告与建议
- 技术交流微信群:添加 wechat id:baidupaddle或扫描下方微信二维码,添加并回复小助手“端侧”,系统自动邀请加入;技术群 QQ 群: 一群696965088(已满) ;二群,959308808;


微信公众号 官方技术交流QQ群
- 如果您对我们的工作感兴趣,也欢迎加入我们 !
版权和许可证
Paddle Lite由 Apache-2.0 license 提供。