(返回顶端)
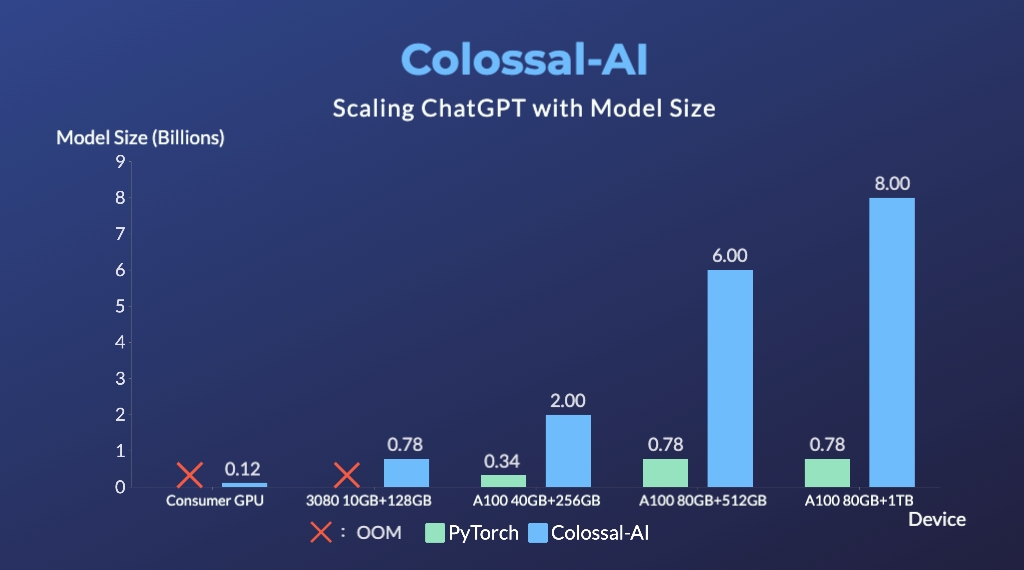
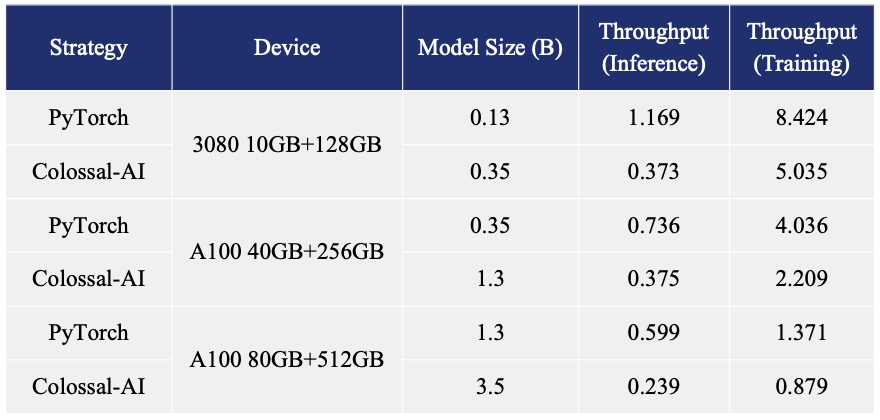
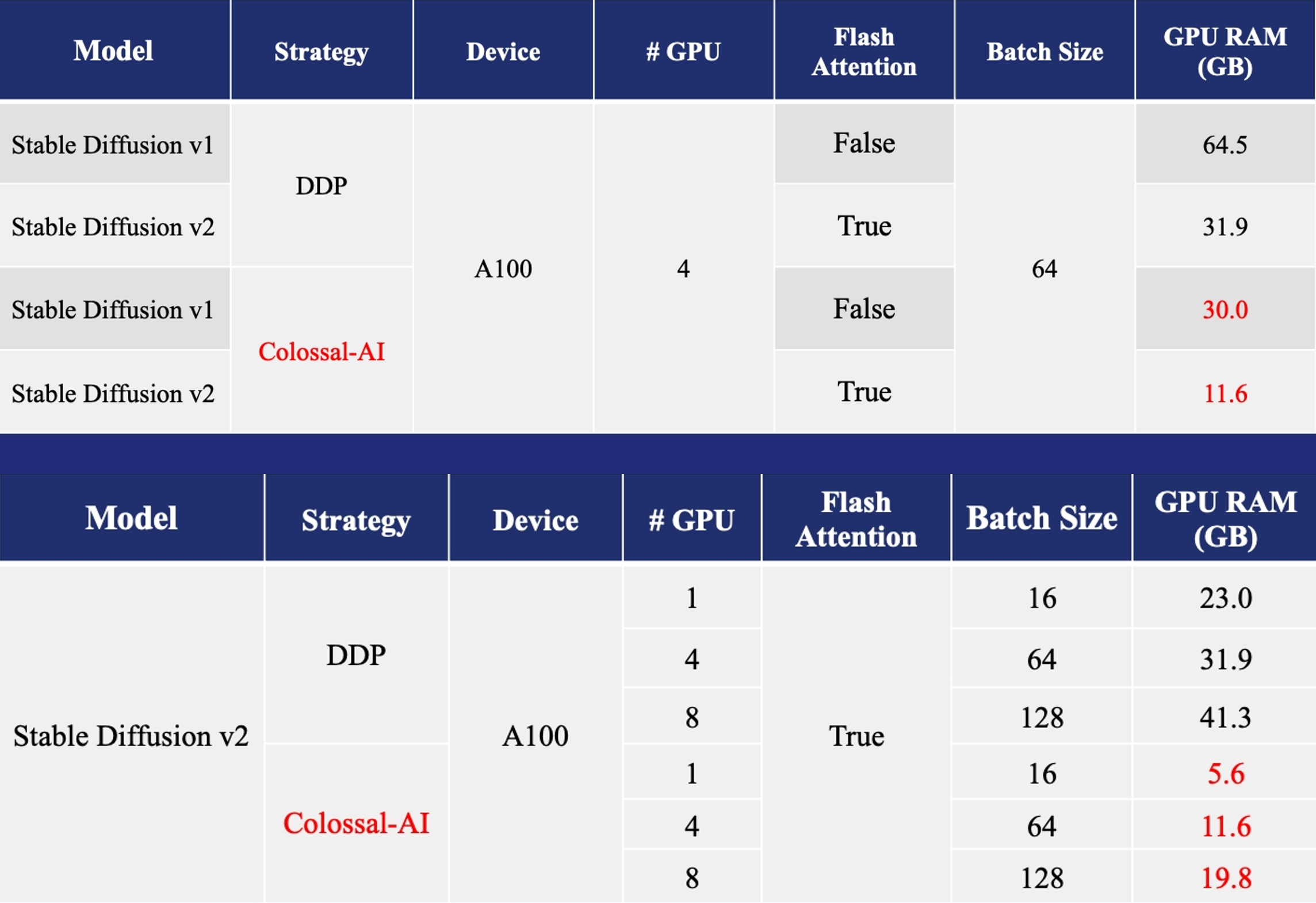
## Colossal-AI 成功案例 ### ColossalChat



(返回顶端)
### 生物医药 加速 [AlphaFold](https://alphafold.ebi.ac.uk/) 蛋白质结构预测

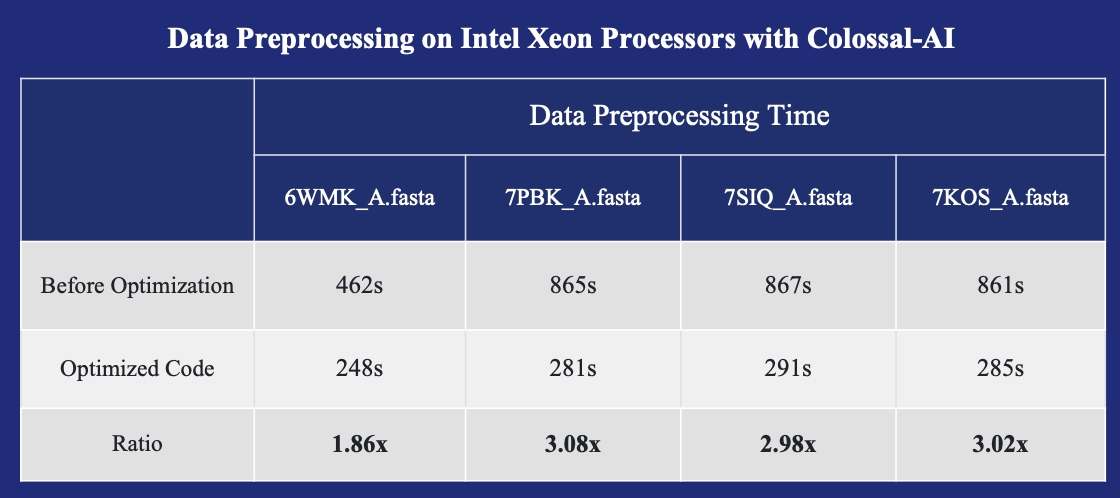
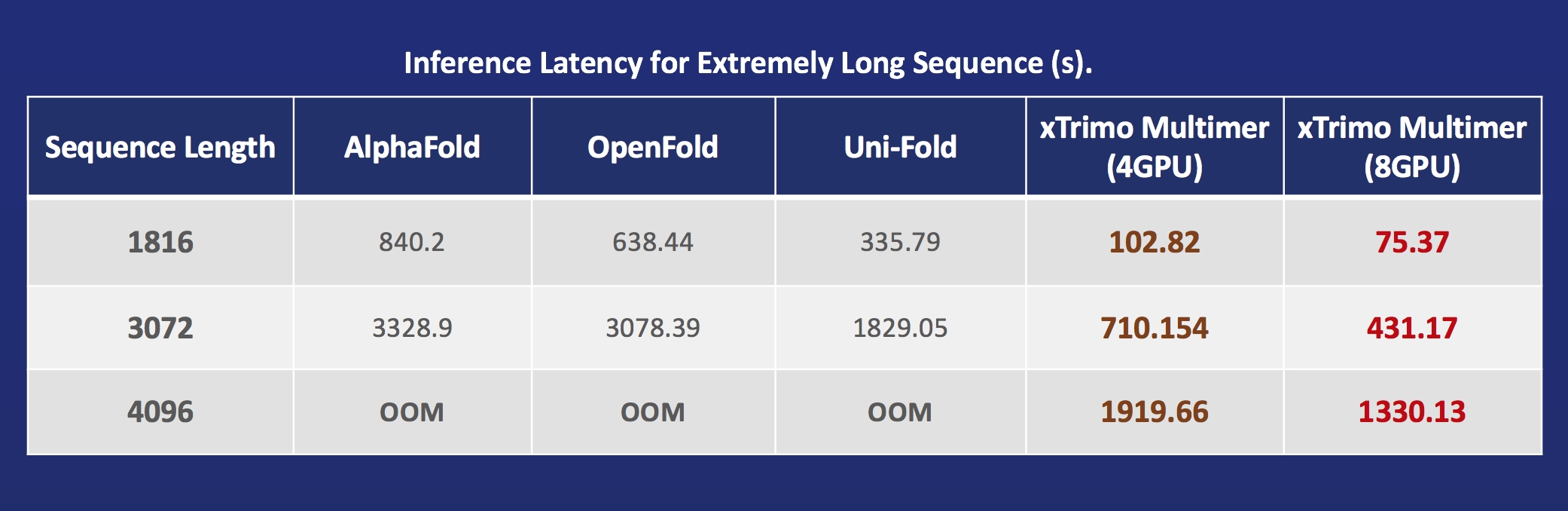
(返回顶端)
## 并行训练样例展示 ### GPT-3
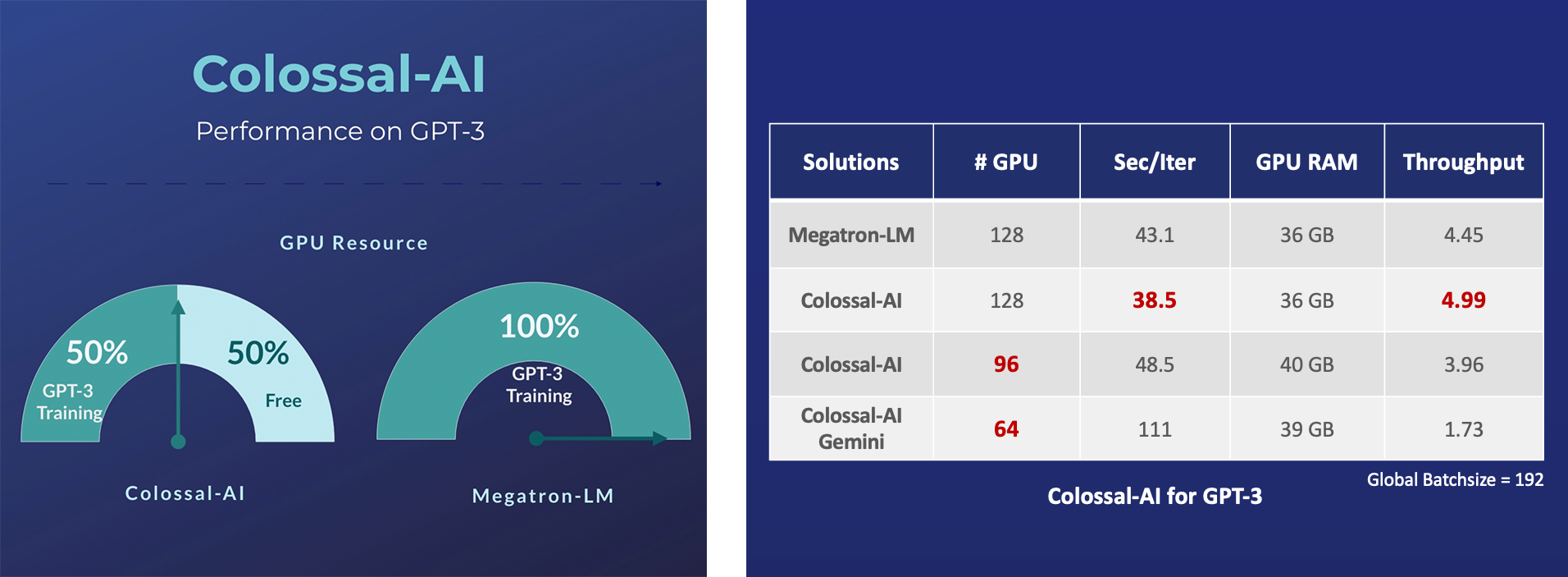
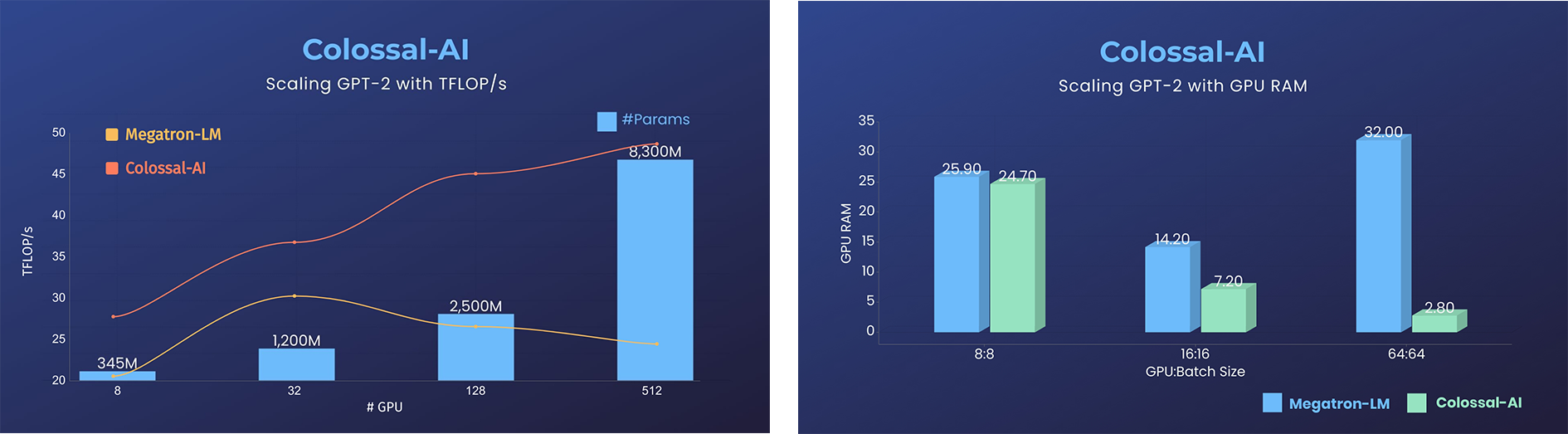 - 降低11倍 GPU 显存占用,或超线性扩展(张量并行)
- 降低11倍 GPU 显存占用,或超线性扩展(张量并行)
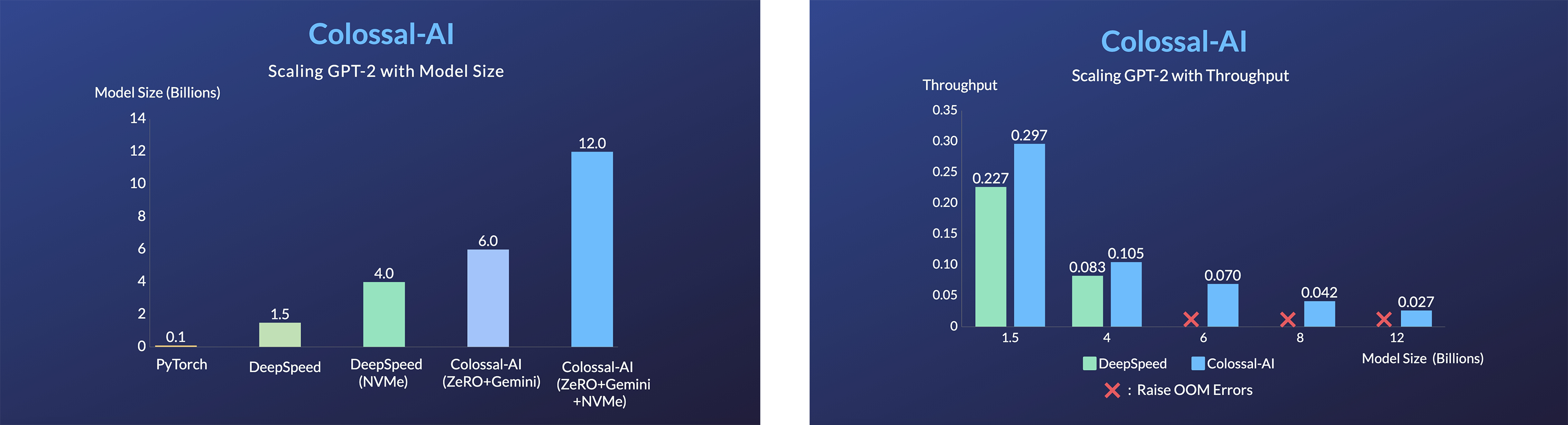
GPT-2.png) - 用相同的硬件训练24倍大的模型
- 超3倍的吞吐量
### BERT
- 用相同的硬件训练24倍大的模型
- 超3倍的吞吐量
### BERT
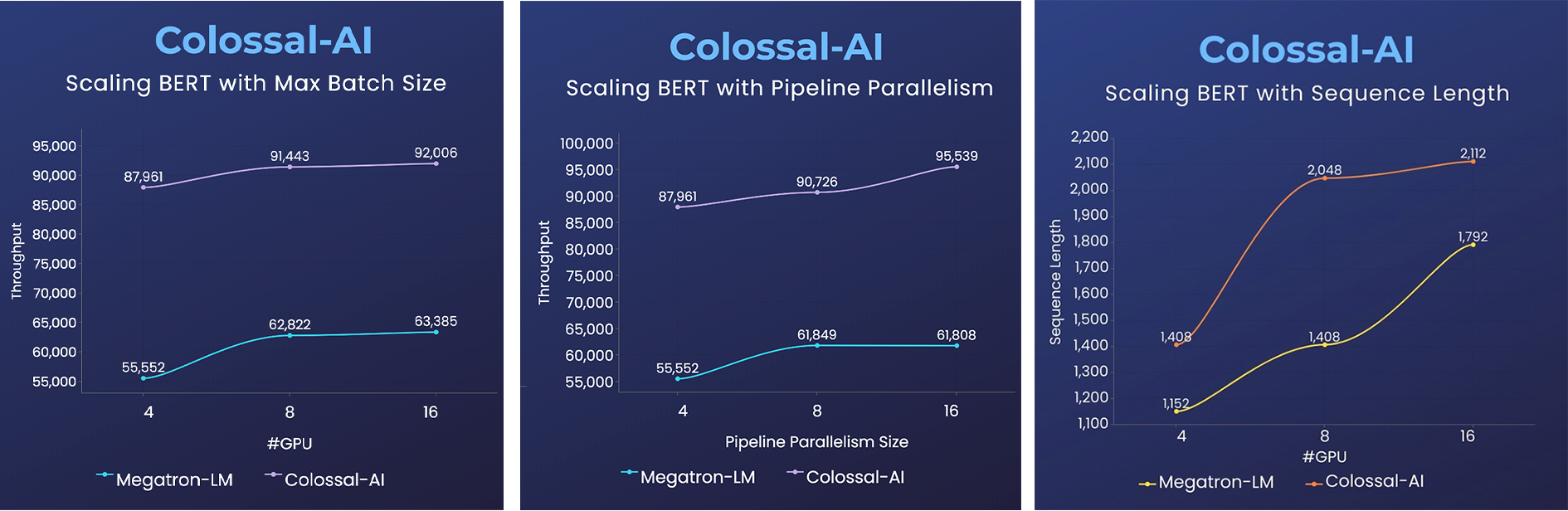 - 2倍训练速度,或1.5倍序列长度
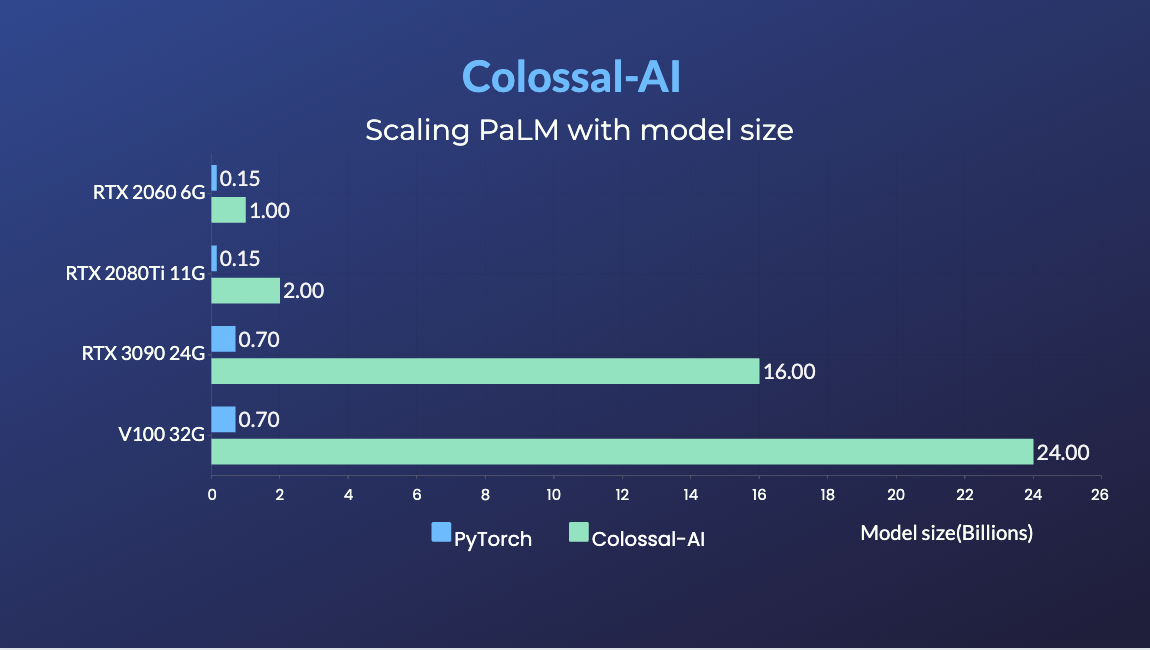
### PaLM
- [PaLM-colossalai](https://github.com/hpcaitech/PaLM-colossalai): 可扩展的谷歌 Pathways Language Model ([PaLM](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html)) 实现。
### OPT
- 2倍训练速度,或1.5倍序列长度
### PaLM
- [PaLM-colossalai](https://github.com/hpcaitech/PaLM-colossalai): 可扩展的谷歌 Pathways Language Model ([PaLM](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html)) 实现。
### OPT
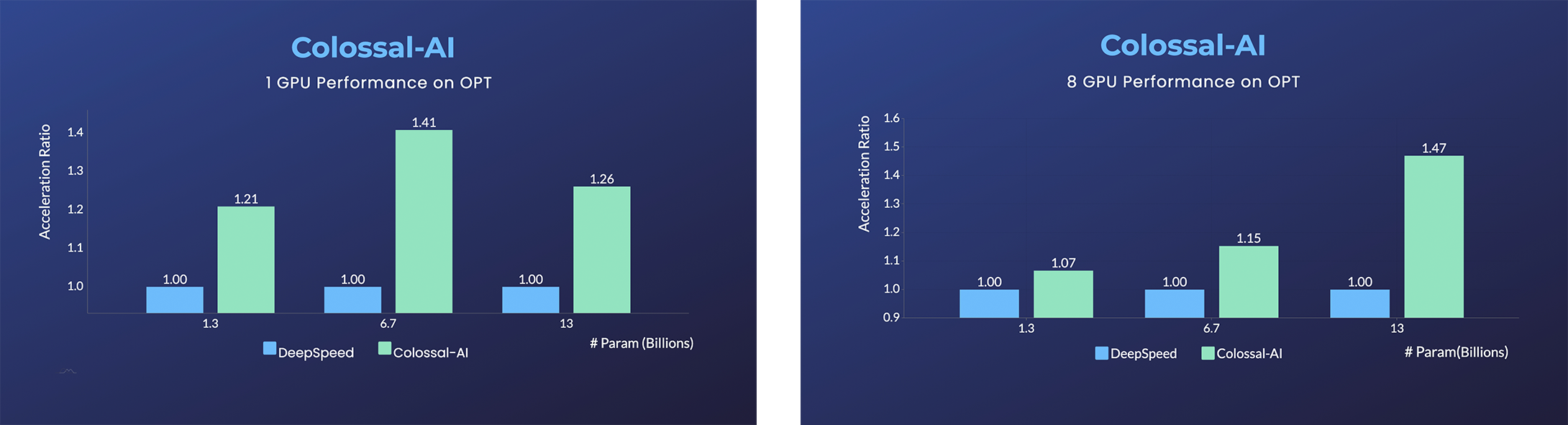 - [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq), 由Meta发布的1750亿语言模型,由于完全公开了预训练参数权重,因此促进了下游任务和应用部署的发展。
- 加速45%,仅用几行代码以低成本微调OPT。[[样例]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/opt) [[在线推理]](https://colossalai.org/docs/advanced_tutorials/opt_service)
请访问我们的 [文档](https://www.colossalai.org/) 和 [例程](https://github.com/hpcaitech/ColossalAI/tree/main/examples) 以了解详情。
### ViT
- [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq), 由Meta发布的1750亿语言模型,由于完全公开了预训练参数权重,因此促进了下游任务和应用部署的发展。
- 加速45%,仅用几行代码以低成本微调OPT。[[样例]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/opt) [[在线推理]](https://colossalai.org/docs/advanced_tutorials/opt_service)
请访问我们的 [文档](https://www.colossalai.org/) 和 [例程](https://github.com/hpcaitech/ColossalAI/tree/main/examples) 以了解详情。
### ViT
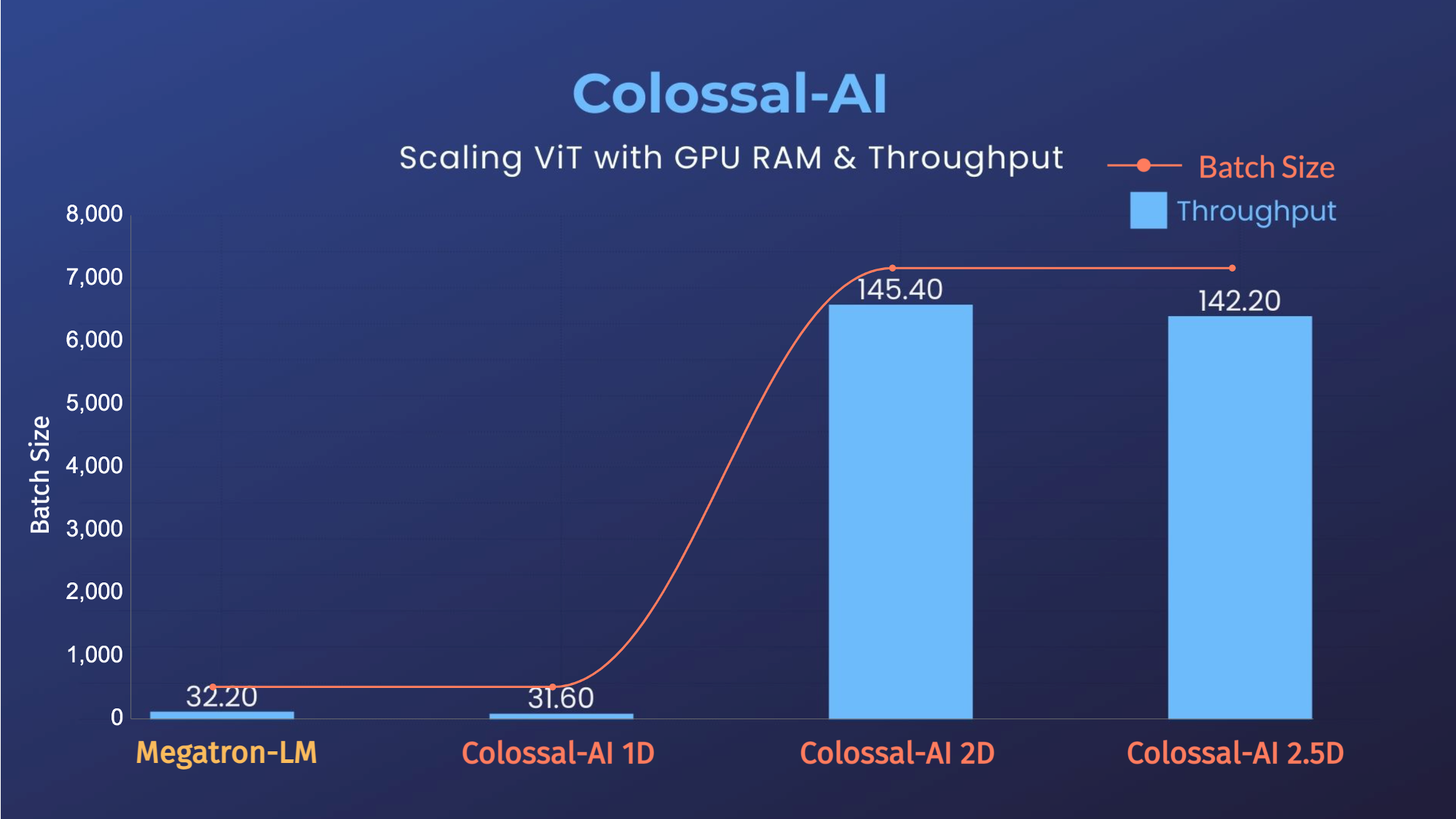
(返回顶端)
## 单GPU训练样例展示 ### GPT-2
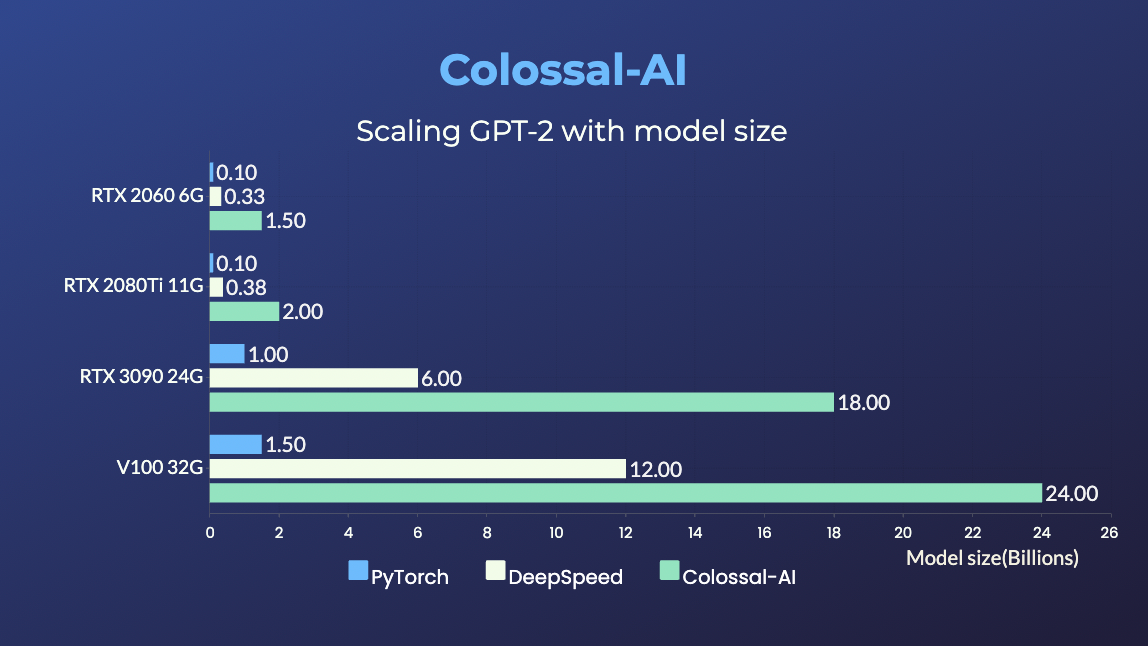
(返回顶端)
## 推理 (Energon-AI) 样例展示
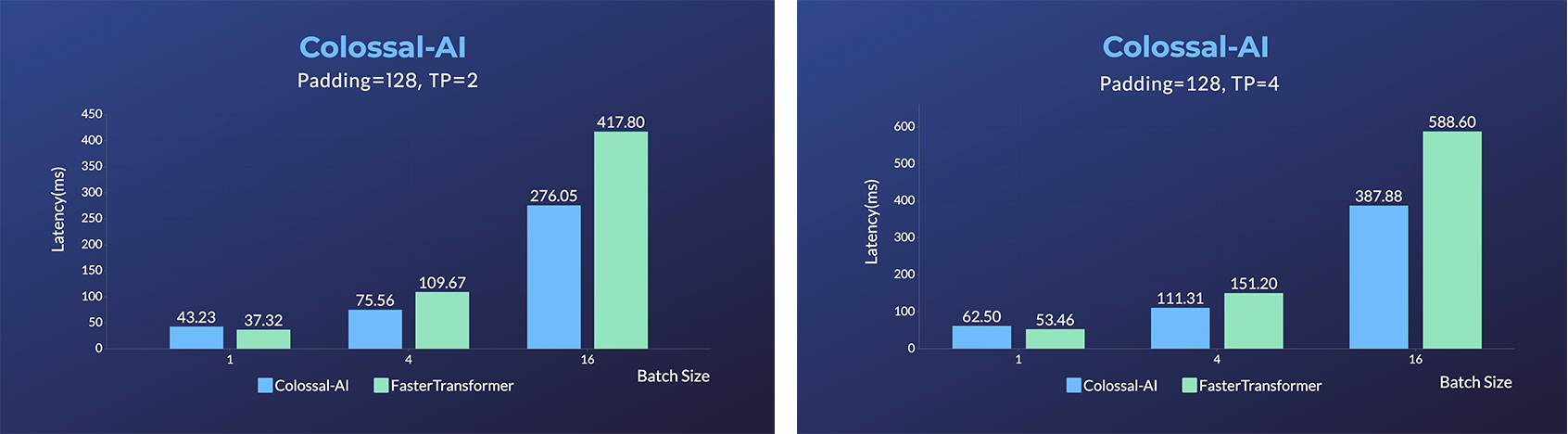
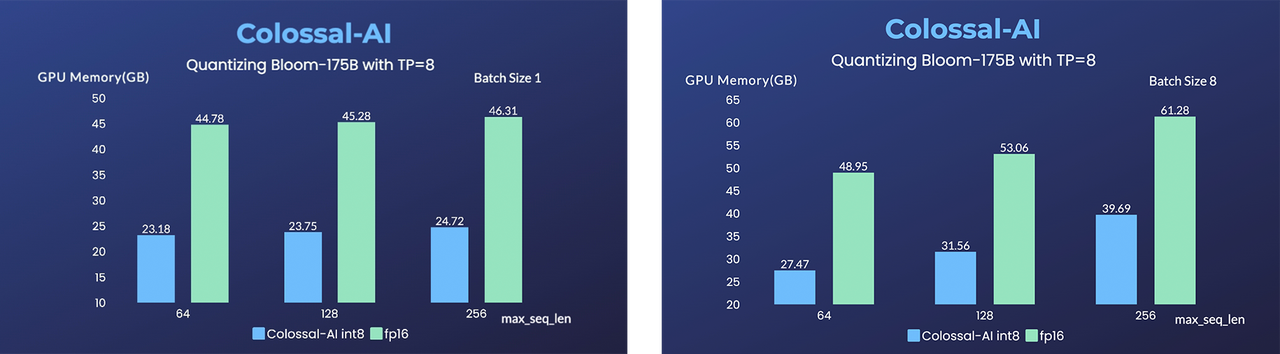
(返回顶端)
## 安装 环境要求: - PyTorch >= 1.11 (PyTorch 2.x 正在适配中) - Python >= 3.7 - CUDA >= 11.0 - [NVIDIA GPU Compute Capability](https://developer.nvidia.com/cuda-gpus) >= 7.0 (V100/RTX20 and higher) - Linux OS 如果你遇到安装问题,可以向本项目 [反馈](https://github.com/hpcaitech/ColossalAI/issues/new/choose)。 ### 从PyPI安装 您可以用下面的命令直接从PyPI上下载并安装Colossal-AI。我们默认不会安装PyTorch扩展包。 ```bash pip install colossalai ``` **注:目前只支持Linux。** 但是,如果你想在安装时就直接构建PyTorch扩展,您可以设置环境变量`CUDA_EXT=1`. ```bash CUDA_EXT=1 pip install colossalai ``` **否则,PyTorch扩展只会在你实际需要使用他们时在运行时里被构建。** 与此同时,我们也每周定时发布Nightly版本,这能让你提前体验到新的feature和bug fix。你可以通过以下命令安装Nightly版本。 ```bash pip install colossalai-nightly ``` ### 从源码安装 > 此文档将与版本库的主分支保持一致。如果您遇到任何问题,欢迎给我们提 issue :) ```shell git clone https://github.com/hpcaitech/ColossalAI.git cd ColossalAI # install dependency pip install -r requirements/requirements.txt # install colossalai pip install . ``` 我们默认在`pip install`时不安装PyTorch扩展,而是在运行时临时编译,如果你想要提前安装这些扩展的话(在使用融合优化器时会用到),可以使用一下命令。 ```shell CUDA_EXT=1 pip install . ```(返回顶端)
## 使用 Docker ### 从DockerHub获取镜像 您可以直接从我们的[DockerHub主页](https://hub.docker.com/r/hpcaitech/colossalai)获取最新的镜像,每一次发布我们都会自动上传最新的镜像。 ### 本地构建镜像 运行以下命令从我们提供的 docker 文件中建立 docker 镜像。 > 在Dockerfile里编译Colossal-AI需要有GPU支持,您需要将Nvidia Docker Runtime设置为默认的Runtime。更多信息可以点击[这里](https://stackoverflow.com/questions/59691207/docker-build-with-nvidia-runtime)。 > 我们推荐从[项目主页](https://www.colossalai.org)直接下载Colossal-AI. ```bash cd ColossalAI docker build -t colossalai ./docker ``` 运行以下命令从以交互式启动 docker 镜像. ```bash docker run -ti --gpus all --rm --ipc=host colossalai bash ```